Overview
I have written a small lab on using user permissions with CosmosDB. This article dwells a bit on the scenarios when to use permissions instead of masterkey and how you can use a set of permissions to grant access to multiple documents, collections, partitions at once.
- Scenarios for user/permissions resource keys
- Implementing Users/Permissions
- Simple sample implementation as LAB
Scenarios for user/permissions resource keys
Before we dive into the details of „How we can work with users/permissions to access data in Cosmos DB“ let’s first discuss some scenarios where that can be applied.
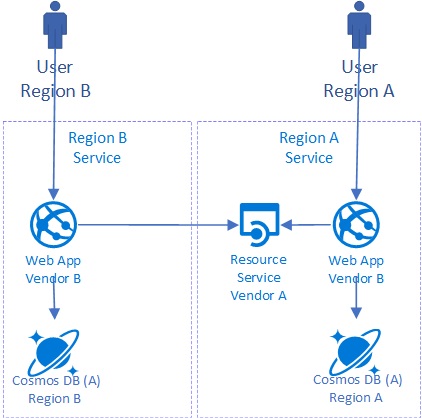
In an ideal scenario we ensure that our authenticated user can access our services only through a limited set of API’s as shown in this simplified architecture:

In this scenario we have two options.
– Option A: Use the master key and ensure access to the right data in the data services depending on the users permissions.
– Option B: Depending on the authenticated user create a set of user permissions (correlating it either directly 1:1 to a cosmos db user, or using a user per tenant) and use this to connect to Cosmos DB in your data services.
In the following scenarios we want to enable direct access to Cosmos DB from applications and services that are not under our full control. We need to ensure that those clients can only access data they are supposed to.
Let’s say the Vendor B needs very fast regional access to the data stored in Cosmos DB. She wants to avoid additional latency by running constantly through business services provided by Vendor A.
In this case Vendor A can grant access to Vendor B’s specific data in Cosmos DB by limiting the access to a single document, single tenant collection or a specific partition within a collection.
Vendor B can use that token/permissions to access the database directly without having access to data of other tenants.
Another scenario might be a mobile application that should be able to fetch the users profile/data quickly directly globally from Cosmos DB.
In this case the application service could provide a resourcetoken/permission to access the database directly. I personally do not like this scenario and would rather use a global distributed API governed by API-Management because that way I have more control in how the user accesses the data (metrics, throttling, additional protection mechanisms). Such a scenario is described with a Xamarin Forms application in the documentation including sample code.

Implementing Users/Permissions
Users are stored within the context of the database in Cosmos DB. Each user has a set of unique named permissions. To learn more about the structure within CosmosDB read this.
Each permission object consists out of
- Token (string)… Access token to access cosmos db
- Id (string)… unique permission id (for user)
- PermissionMode… either Read or All
- ResourceId (string)… ID of the resource the permission applies to
- ResourceLink (string)… Self-Link to resource where perm apply.
- ResourcePartitionKey (string)… PartitionKey of resource perm applies.
Once you have acquired a permission you need only to transfer the Token to the client that should access Cosmos DB. A token is represented as a string.
// token: "type=resource&ver=1&sig=uobSDos7JRdEUfj ... w==;" string tokenToTransfer = permission.Token;
The client can create a connection to Cosmos DB using that token.
DocumentClient userClient = new DocumentClient(
new Uri(docDBEndPoint),
transferedToken);
!Important! The token stays valid until it expires even if you delete the permission in Cosmos DB. The expiration time can be configured!
You can access multiple resources by providing a set of Permissions. Use the constructor allowing to pass a list of Permissions.
Serializing and Deserializing those permissions as JSON strings is a bit painfully:
Serialization:
// Serializing to JSON MemoryStream memStream = new MemoryStream(); somePermission.SaveTo(memStream); memStream.Position = 0L; StreamReader sr = new StreamReader(memStream); string jsonPermission = sr.ReadToEnd();
The serialized token looks like this:
{
"permissionMode":"Read",
"resource":"dbs/q0dwAA==/colls/q0dwAIDfWAU=/",
"resourcePartitionKey":["apollak"],
"id":"mydata",
"_rid":"q0dwAHOyMQBzifcvvscGAA==",
"_self":"dbs/q0dwAA==/users/q0dwAHOyMQA=/permissions/q0dw ... AA==/",
"_etag":"\"00001500-0000-0000-0000-5aaa4a6b0000\"",
"_token":"type=resource&ver=1&sig=uobSD ... 2kWYxA==;2L9WD ... Yxw==;",
"_ts":1521109611
}
De-serialization:
memStream = new MemoryStream(); StreamWriter sw = new StreamWriter(memStream); sw.Write(jsonPermission); sw.Flush(); memStream.Position = 0L; Permission somePermission = Permission.LoadFrom<Permission>(memStream); sw.Close();
By adding multiple permissions to a list you can create a document client with access to multiple resources (f.e. 1..n documents, 1..n collections, 1..n partitions).
List<Permission> permList = new List<Permission>();
// adding two permissions
permList.Add(Permission.LoadFrom<Permission>(memStream));
permList.Add(lpollakDataPermission);
DocumentClient userClient = new DocumentClient(
new Uri(docDBEndPoint,UriKind.Absolute),
permList);
Important things to know:
– If you restrict the partition with a Permission you MUST always set the partition key accessing CosmosDB!
– Permission IDs must be unique for each user and must not be longer than 255 characters
– Tokens expire after an hour per default. You can set an expiration starting by 10 minutes up to 24 hours. This is passed within the RequestOptions in seconds.
– Each time you read the permission from the permission feed of a user a new token gets generated
Example to customize the expiration time
lpollakDataPermission = await client.UpsertPermissionAsync(
UriFactory.CreateUserUri(dbName, apollakUserid),
lpollakDataPermission,
new RequestOptions() { ResourceTokenExpirySeconds = 600});
Simple sample implementation as LAB
I have written a small LAB that you can use with CosmosDB Emulator to play with the permissions. There is a student version to start from and also a finished version. In the project folder you will find a „ReadMe.md“ file describing the steps. Download Cosmos DB Security Lab




























 by Andreas Pollak")
 by Rainer Stropek")














